Review LLM Options
Info on supported LLM performance, cost, latency and licensing designed to help you short-list LLMs for testing
Konko AI provides fully managed access to the following top performing LLMs:
- Meta-Llama-2-13b-chat
- Meta-Llama-2-7b-chat
- Defog-sqlcoder2
- CodeLlama-34b-Instruct-hf
- CodeLlama-34b-Python-hf
- Bigcode-starcoder
- Mistral-7B-v0.1
- Togethercomputer-Llama-2-7B-32K-Instruct
- Tiiuae-falcon-40b
Additionally, it provides proxy access to prominent OpenAI models such as:
- GPT-4
- GPT-3.5
These models can be accessed through Konko AI's generate endpoint free of charge. This means you can test these models without setting up any inferencing infrastructure or paying per hour for GPUs.
Once you are done testing you can move to production by following these steps outlined here.
These models were curated based on overall performance at text-generation tasks and availability for commercial use.
Factors to Consider When Selecting an LLM
When it comes to integrating LLMs into your workflows, various factors must be meticulously evaluated to ensure alignment with use-cases, technical requisites, and budgetary limits:
- Performance
- Detailed Understanding: Acknowledge the variance in LLM performance based on data, parameters, and training methods.
- Improvement Strategies: Leverage techniques like RAG and fine-tuning to enhance model effectiveness.
- Latency and Model Size
- Speed vs. Size Trade-Off: A mindful equilibrium between the model's computational speed and size, ensuring optimal functionality.
- Capacity vs. Cost: Navigate through decisions that balance the prowess of larger models with feasible budgetary outlines.
- Financial Viability
- Computational Expenditure: Acknowledge larger models often bring about higher computational and financial demands.
- Proprietary Costs: Especially note that proprietary models, like those from OpenAI, come with substantial financial requisites.
- Context Window Length
- Input Management: Ensure that the chosen LLM can effectively handle your necessary input size.
- Output Relevancy: Ensure outputs remain relevant and comprehensible in relation to the input.
- Linguistic Competency
- Language Proficiency: Ensure proficiency in the languages pertinent to your user base and data sets.
- Multilingual Capabilities: In instances of multiple languages, evaluate the model’s adaptability and accuracy across languages.
Supported LLMs - Basic Information
| LLM | Top use-cases | Open Source | Licensable for commercial use? | Context window | Latency (vs. GPT-4 ) | Cost (vs. GPT-4) | Top languages | Status |
|---|---|---|---|---|---|---|---|---|
| Meta-Llama-2-70b-chat | Yes | Yes (Llama 2 License) | 4,096 | |||||
| Meta-Llama-2-13b-chat | Yes | Yes (Llama 2 License) | 4,096 | |||||
| GPT-4 | No | Yes (OpenAI License) | 8,192 - 32,768 | |||||
| GPT-3.5 | No | Yes (OpenAI License) | 4,096 - 16,384 |
Supported LLMs - Performance Benchmarking
The table below is meant to give Konko users a sense for the comparative performance of each model across a variety of tests. This is means to inform your model evaluation and testing process.
Model performance is expressed in terms of percentile rank against other LLMs within the Open LLM Leaderboard across a variety of tasks
| LLM | Average across tests | Reasoning (Al2 challenge) | Common Sense (HellaSwag test) | Accuracy (MMLU test) | Factualness (Truthful QA test) |
|---|---|---|---|---|---|
| Meta-Llama-2-70b-chat | 92nd percentile | 91st percentile | 93rd percentile | 92nd percentile | 46th percentile |
| Meta-Llama-2-13b-chat | 72nd percentile | 72nd percentile | 72nd percentile | 73rd percentile | 46th percentile |
| GPT-4 | 100th percentile | 100th percentile | 100th percentile | 100th percentile | 98th percentile |
| GPT-3.5 | 99th percentile | 100th percentile | 91st percentile | 97th percentile | 59th percentile |
How to read this chart: "92nd percentile" means that the model outperforms 92% of models within the Open LLM Leaderboard
Source Note: The scores for GPT-3.5 and GPT-4 have been derived from their respective research papers.
Sources: HuggingFace, Eleuther AI Language Model Evaluation Harness
The scores above are indicative. They reflect performance across 5 key tests:
- AI2 Reasoning Challenge (25-shot) - a set of grade-school science questions.
- HellaSwag (10-shot) - a test of commonsense inference, which is easy for humans (~95%) but challenging for SOTA models.
- MMLU (5-shot) - a test to measure a text model’s multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more.
- TruthfulQA (0-shot) - a test to measure a model’s propensity to reproduce falsehoods commonly found online.
We chose these measures of performance as they test the LLMs across a variety of tasks (reasoning, common sense, accuracy and factualness).
Supported LLMs - Inference Speed and Cost
Below we show indicative inference speed and cost ranges for Konko AI supported models.
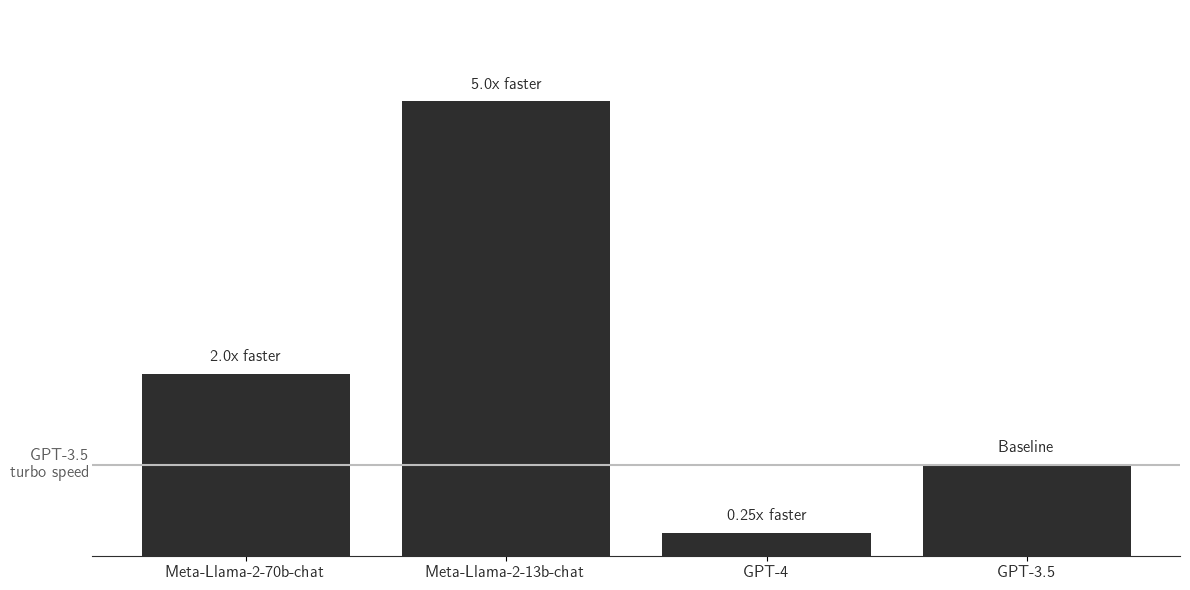
- Speed ranges are expressed on a millisecond per token basis
- Cost ranges are expressed as a percentage of inference cost for GPT-3.5 turbo
The speed and cost ranges reflect the inherent tradeoff between hardware performance and cost: Konko AI supported LLMs can run on a range of GPUs. Larger, more powerful GPUs will offer faster inference at a higher cost
Konko AI supported model speed (relative to GPT-3.5 turbo speed)
Konko AI supported model inference cost (as a % of GPT-3.5 turbo cost)
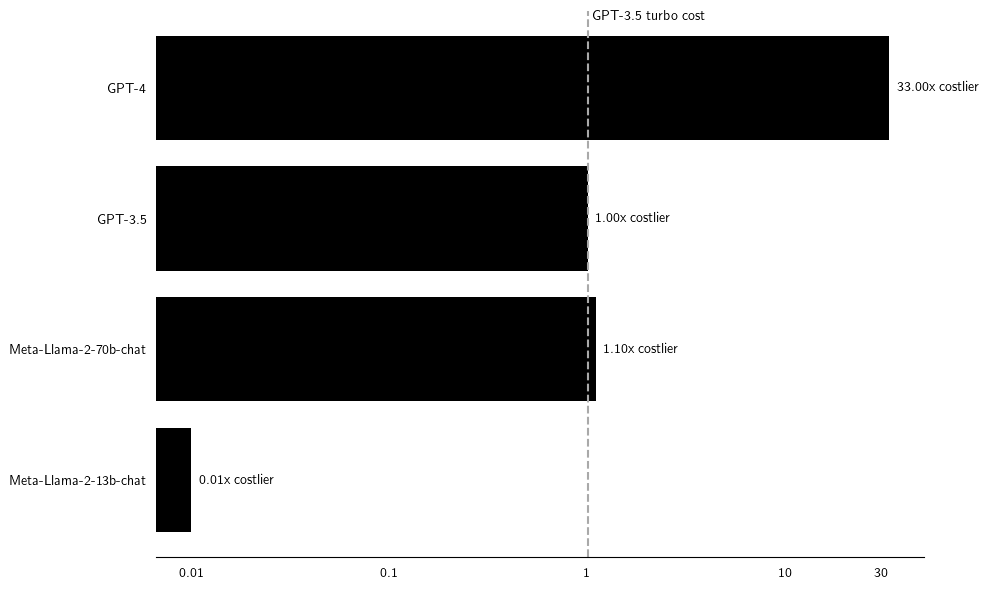
Note: cost figures assume GPT-3.5 Turbo 4k context (this is the cheapest version of GPT-3.5 Turbo)
Requesting additional LLMs
We are constantly evaluating the LLM landscape and adding top-performing and commercially usable LLMs to our list of supported models as they come out
If you would like to request additional LLMs to be included within the Konko API's generate end-point please email us at [email protected] and tell us why
Updated 9 months ago