Meta - Llama 2-70b-Chat
Llama 2-70b-Chat - Snapshot
Meta's Llama 2-70b-Chat is a part of the Llama 2 collection, which is specifically refined for dialogue applications.
| LLM | Meta - Llama 2-70b |
|---|---|
| Release date | July 2023 |
| Open source? | Yes |
| Licensable for commercial use? | Yes (License: Llama 2 License) |
| Context window length (# of tokens) | 4,096 |
| Performance ranking | 92nd percentile |
| Cost (per 10M tokens) | ~ a dollar (1.1x the price of GPT-3.5 but 30x cheaper than GPT-4) |
| Speed (ms / token) | 40-60 ms per token (up to 2x faster than GPT-3.5 turbo) |
Note - performance rankings based on Open LLM Leaderboards
Why we've included this LLM within Konko API?
Meta's Llama 2-70b-Chat is among the highest performing Open Source LLMs across benchmarks:
A few differentiating factors:
- Enterprise Deployment & Performance: matches top models like ChatGPT and PaLM-Bison in benchmarks. Yet, its enterprise use poses significant deployment challenges. Incorporating it into Konko mitigates these, offering users optimal performance without the usual complexities.
- 4k context window: this is double what most LLMs offer leading to a superior ability to understand complex contexts and deliver high-quality, high-precision output.
- Grouped-query attention framework: which balances inference resource consumption and output quality (Ainslie et al., 2023)
- Large Pre-training Corpus: 2T training set (40% more tokens than Llama) improving inference quality (for reference OpenAI's GPT-3 was trained on 300B tokens)
- Safety Measures: trained with Reinforcement Learning with Human Feedback (RLHF) and Supervised Fine-Tuning (SFT) to better align with human preferences for safety and helpfulness.
Meta's Llama 2-70b-Chat - Performance Benchmarking
The chart below shows Llama 2-70b-Chat's performance relative to other LLMs within the Open LLM Leaderboard across a variety of benchmarks testing several facets of performance.
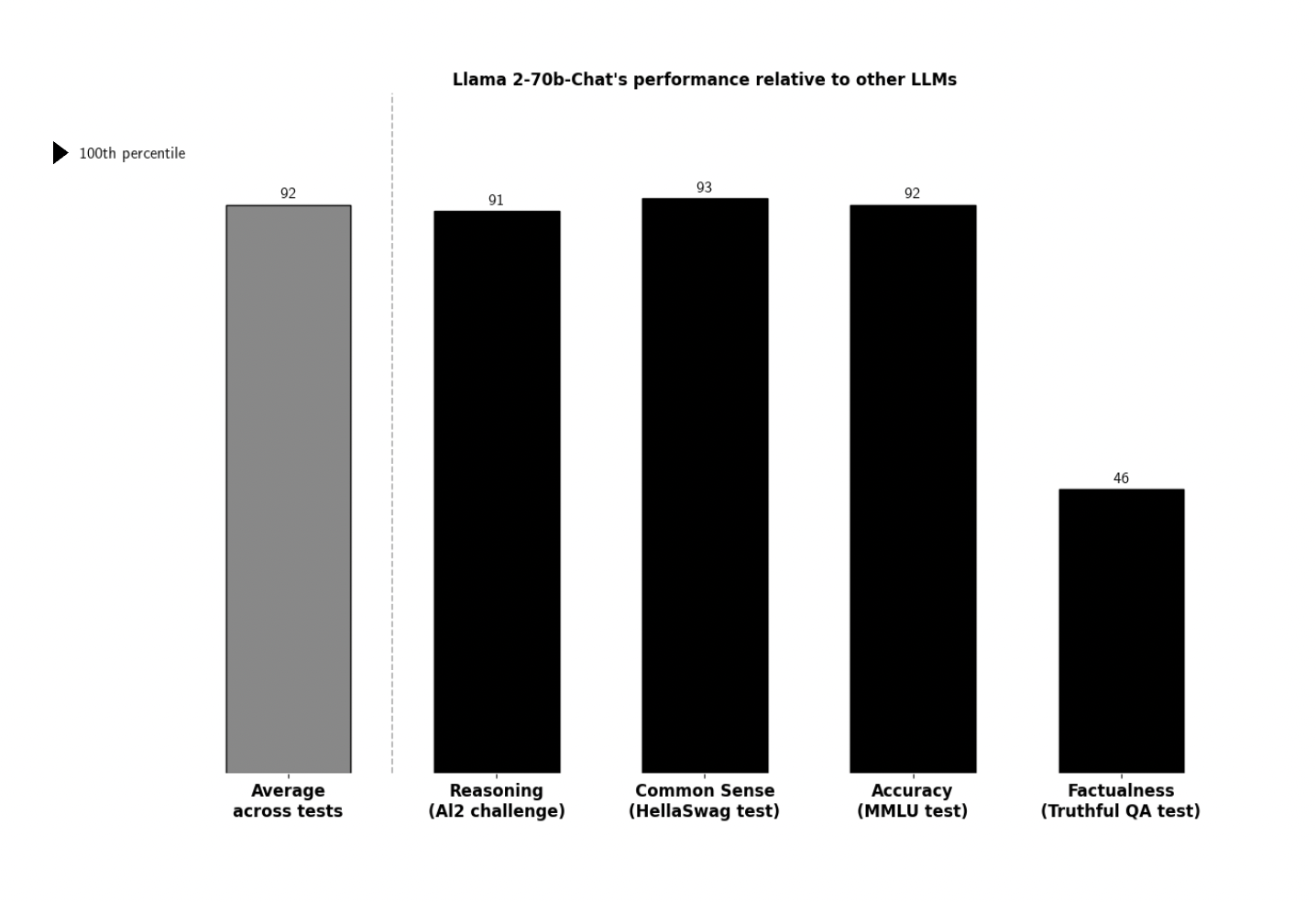
How to read this chart: "67th percentile" means that the model outperforms 67% of models within the Open LLM Leaderboard
Sources: HuggingFace, Eleuther AI Language Model Evaluation Harness
Prompting
When a user calls on Meta's Llama 2-70b-Chat through the Konko API's ChatCompletion endpoint, Konko API automatically inserts the user's prompt into the prompt template that Llama 2-70b-Chat was trained on (see below)
Prompt template that Llama 2-70b-Chat was trained on:
"You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
prompt"
This prompt template has been shown to produce the strong results for Llama 2-70b-Chat
To illustrate, assume I want query Llama 2-70b-Chat to generate a summary of the book 'Sapiens' by Yuval Noah Harari:
response = konko.ChatCompletion.create(
model="meta-llama/Llama-2-70b-chat-hf",
messages= [
{"role": "user", "content": "generate a summary of the book 'Sapiens' by Yuval Noah Harari"},
],
max_tokens=500,
)
The prompt "generate a summary of the book 'Sapiens' by Yuval Noah Harari" is automatically inserted into the prompt template above prior to being sent out to Llama 2-70b-Chat.
In other words, Llama 2-70b-Chat receives the following prompt:
" You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
generate a summary of the book 'Sapiens' by Yuval Noah Harari"
In this prompt, there are two parts.
- User message: Direct queries like "How can I optimize my website for SEO?"
- System prompt: Background instruction. E.g., "You're an SEO expert." It dictates the model's tone and approach. Although Konko has a recommended system prompt, you can tailor it to fit specific needs.
For extended chats, a third component emerges: the model's response.
If you're leveraging Llama2-70B-Chat for business analysis, consider using a system prompt like:
"You're a market analysis expert. Provide succinct and actionable insights based on global market trends."
With a user query: "What are the emerging e-commerce trends in Europe?"
Such tailoring ensures the model resonates with the desired expertise and tone, optimizing outputs for specific scenarios.
Prompting for chat use-cases
If you are using Llama 2 70b-Chat to build a chat application, you need to mark the user's portion of past dialogue turns with instructions tags that indicate the beginning ("[INST]") and end ("[/INST]") of the user's input.
For example, a properly formatted dialogue looks like:
"[INST] Who wrote the book Sapiens? [/INST]
Yuval Noah Harari wrote Sapiens.
[INST] Can you please generate a summary of the book 'Sapiens'? [/INST]"
In this example, the hypothetical user has first prompted "Who wrote the book Sapiens?" and received the response "Yuval Noah Harari wrote Sapiens" from Llama 2 70b-Chat. Then, the user asked "Can you please generate a summary of the book Sapiens?".
Tagging the human portion of the dialogue ensures that Llama 2 70b-Chat has a proper understanding of relevant context for future queries.
Training Dataset
The Llama 2 LLM family was trained on 2T tokens (primarily in English and from publicly available source)
Meta has not disclosed the training data mix that was used for the Llama 2 LLMs
Data Freshness : Llama 2 LLMs' training data has a cutoff date of September 2022, but some tuning data is as recent as July 2023.
Fine-Tuning for Chat: leverages over a million human annotations and publicly available instruction datasets.(Meta has not disclosed the fine-tuning dataset)
Limitations and Biases
As with any LLM, Llama 2-70b-Chat may produce outputs that contain inaccuracies. The model has been trained predominantly in English and across a range of situations that couldn't possibly cover every possible circumstance. As such, there is a chance that it might respond to certain prompts with results that are biased, inappropriate, or otherwise objectionable.
For more details, please visit the Responsible Use Guide.
Updated 9 months ago